
DeepSeek又回来了!国产大模型仍然能打!
来源: 原创 作者:中国软件网 2025-12-02 11:02:54
DeepSeek发布新版本啦!
DeepSeek发布新版本啦!
等了那么久,终于等到新版本。从年初的惊艳,我相信,它又迎来了再次惊艳!
说实话,自从OpenAI GPT5.1发布之后,尤其是Google的Gemini3.0发布之后,我曾一度觉得,国产大模型这下该着急了!因为,在算力不足的情况下,国产大模型似乎难以和国外大模型抗衡了!
况且,DeepSeek似乎已消沉。
那么久没有新版本发布!
今天(12月1日),它终于又回来啦 !
今天下午18:52,DeepSeek同时发布两个正式版模型:DeepSeek-V3.2和 DeepSeek-V3.2-Speciale。
据DeepSeek公众号介绍:官方网页端、App 和 API 均已更新为正式版DeepSeek-V3.2。Speciale 版本目前仅以临时 API 服务形式开放,以供社区评测与研究。
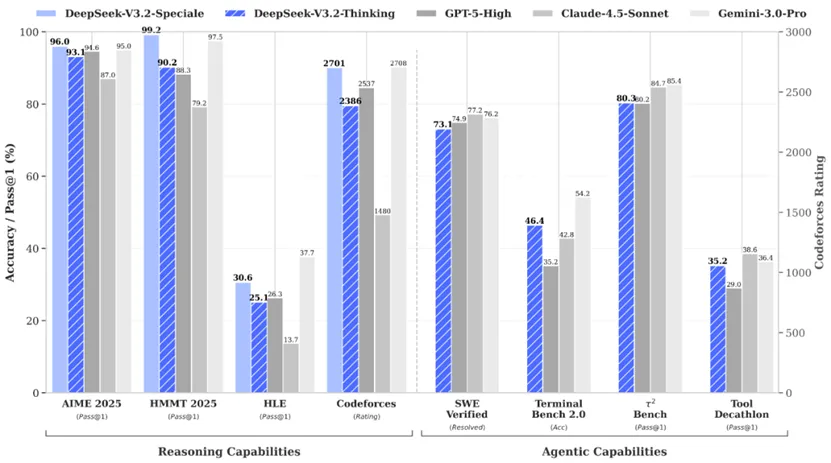
DeepSeek自己给自己的评价是:推理能力全球领先。
她自己介绍说,DeepSeek-V3.2的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用 Agent任务场景。在公开的推理类 Benchmark 测试中,DeepSeek-V3.2达到了 GPT-5 的水平,仅略低于Gemini-3.0-Pro;相比 Kimi-K2-Thinking,V3.2 的输出长度大幅降低,显著减少了计算开销与用户等待时间。
DeepSeek-V3.2-Speciale的目标是将开源模型的推理能力推向极致,探索模型能力的边界。V3.2-Speciale是 DeepSeek-V3.2 的长思考增强版,同时结合了DeepSeek-Math-V2 的定理证明能力。该模型具备出色的指令跟随、严谨的数学证明与逻辑验证能力,在主流推理基准测试上的性能表现媲美 Gemini-3.0-Pro(见表1)。
有意思的是,DeepSeek自己还介绍,在高度复杂任务上,Speciale 模型大幅优于标准版本,但消耗的 Tokens 也显著更多,成本更高。目前,DeepSeek-V3.2-Speciale 仅供研究使用,不支持工具调用,暂未针对日常对话与写作任务进行专项优化。
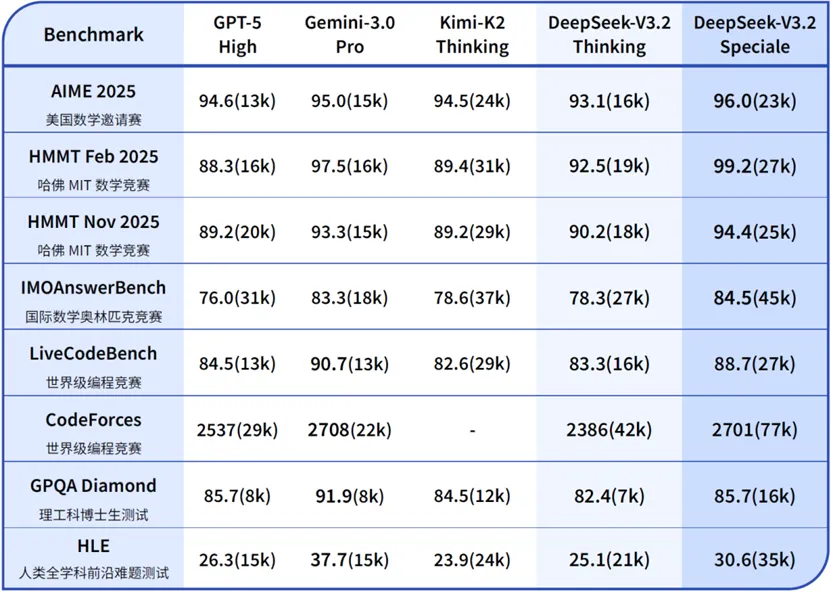
DeepSeek官方介绍说,新模型的一大特点是:思考融入工具调用。
不同于过往版本在思考模式下无法调用工具的局限,DeepSeek-V3.2 是他们推出的首个将思考融入工具使用的模型,并且同时支持思考模式与非思考模式的工具调用。DeepSeek提出了一种大规模 Agent 训练数据合成方法,构造了大量「难解答,易验证」的强化学习任务(1800+ 环境,85,000+ 复杂指令),大幅提高了模型的泛化能力。
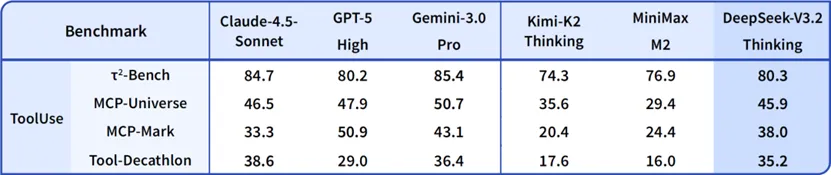
DeepSeek-V3.2模型在智能体评测中达到了当前开源模型的最高水平,大幅缩小了开源模型与闭源模型的差距。值得说明的是,V3.2 并没有针对这些测试集的工具进行特殊训练,所以我们相信,V3.2 在真实应用场景中能够展现出较强的泛化性。
示例为通过 LobeChat 使用DeepSeek-V3.2 的深度思考+工具调用能力得到更加详细准确的回复
从DeepSeek这次的表现来看,我对国产大模型的信心又回来了。甚至我认为,未来大模型的技术创新,将由中国主导。美国因为算力充足,不缺“卡”,因此大模型的创新主要依靠算力。而中国因为缺乏算力,则会将创新主要集中在算法。这体现了创新的本质!
因此,未来全世界的开源大模型,将会中国主导技术创新力量。
免责声明: 该文观点仅代表作者本人,Soft6软件网系信息发布平台,Soft6软件网仅提供信息存储空间服务。 未经允许不得转载,授权事宜请联系:support@soft6.com 如对本稿件有异议或投诉,请查看《版权保护投诉指引》
您可能还喜欢这些资讯